
티스토리 뷰
JPQL JOIN
1. 내부 조인
연관 필드를 사용해서 조인해야한다. (m.team t)
- SQL의 조인과는 달리 두 엔티티를 조인하면 조인 결과의 m 엔티티만 가져온다.
String teamName = "팀A";
String query = "SELECT m FROM Member m JOIN m.team t " + "WHERE t.name = :teamName";
List<Member> members = em.createQuery(query, Member.class)
.setParameter("teamName", teamName)
.getResultList();-- inner join sql
SELECT
M.ID AS ID,
M.AGE AS AGE,
M.TEAM_ID AS TEAM_ID,
M.NAME AS NAME
FROM
MEMBER M INNER JOIN T ON M.TEAM_ID = T.ID
WHERE
T.NAME = ?// 두 엔티티를 모두 가져오고 싶은 경우 (TypedQuery 사용 X)
String query = "SELECT m, t FROM Member m JOIN m.team t";2. 외부 조인
String query = "SELECT m FROM Member m LEFT JOIN m.team t";-- outer left join sql
SELECT
M.ID AS ID,
M.AGE AS AGE,
M.TEAM_ID AS TEAM_ID,
M.NAME AS NAME
FROM
MEMBER M LEFT JOIN TEAM T ON M.TEAM_ID = T.ID
WHERE
T.NAME = ?3. 컬렉션 조인
일대다, 다대다 처럼 조인할 때 컬렉션 값 연관 필드를 사용하는 경우를 컬렉션 조인이라 한다.
String query = "SELECT t, m FROM TEAM t LEFT JOIN t.members m"4. 세타 조인
전혀 관계없는 두 테이블을 조인하고 싶을 때 사용한다.
- 내부 조인만 지원한다.
String query = "SELECT COUNT(m) FROM Member m, TEAM t WHERE m.username = t.name";-- sql
SELECT COUNT(M.ID)
FROM
MEMBER M CROSS JOIN TEAM T
WHERE
M.USERNAME = T.NAME5. JOIN ON
ON을 사용해서 조인 대상을 필터링 가능
INNER JOIN: WHERE 절의 결과와 동일하기 때문에 주로 WHERE를 사용OUTER JOIN: 조건을 주고 싶을 때 사용 (ex. 연관관계가 없는 두 엔티티를 조인할 때 유용)
String query = "SELECT m, t FROM Member m LEFT JOIN Team t ON m.username = t.name";6. 페치 조인
연관된 엔티티나 컬렉션을 한 번에 같이 조회하는 기능
연관된 엔티티들을 함께 조회하기 때문에 SQL 호출 회수를 줄여 성능 최적화를 할 수 있다.
별칭을 사용할 수 없다. (하이버네이트는 허용하지만 사용 X)
글로벌 로딩 전략보다 우선된다.
지연 로딩의 경우: 지연 로딩이 발생하지 않고 프록시가 아닌 실제 엔티티를 가져온다.실제 엔티티이므로 준영속 상태가 되어도 조회 가능
N + 1문제를 해결할 수 있다. (100% 해결하는 것은 아님.)
6.1 N + 1 문제
요청이 1개의 쿼리만 처리하도록 기대했지만 N개의 추가 쿼리가 나가는 상황
6.2 엔티티 페치 조인
<다대일의 경우>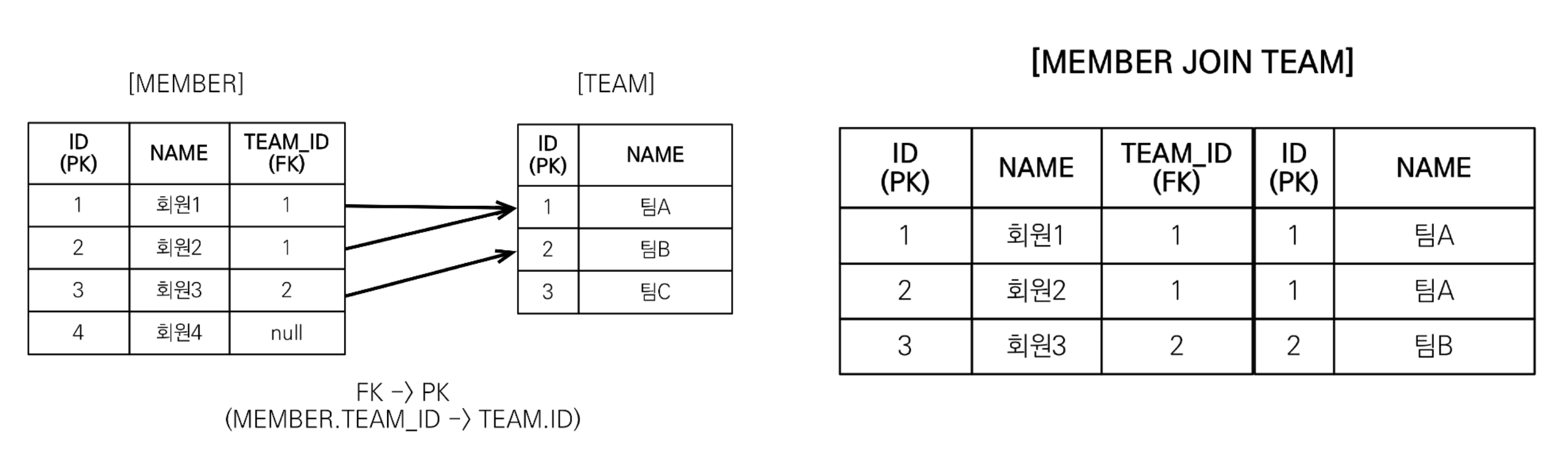
String query = "SELECT m FROM Member m JOIN fetch m.team";
List<Member> members = em.createQuery(query, Member.class)
.getResultList();
for (Member member : members) {
System.out.println("username = " + member.getUsername() + ", " + "teamname = " + member.getTeam().name());
}
/* 결과
username = 회원1, teamname = 팀A
username = 회원2, teamname = 팀A
username = 회원3, teamname = 팀B
*/SELECT M.*, T.*
FROM MEMBER M
INNER JOIN TEAM T ON M.TEAM_ID = T.ID6.3 컬렉션 페치 조인
<일대다의 경우>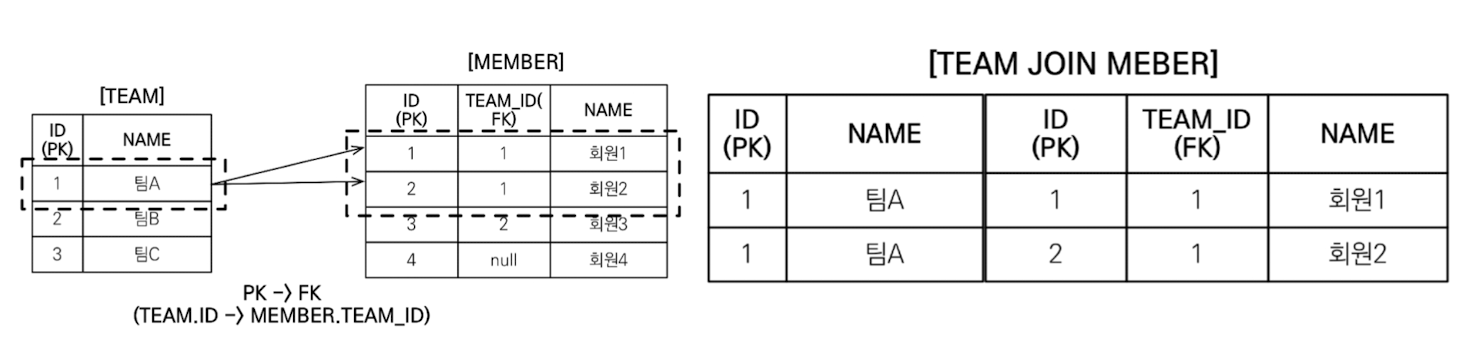
String query = "select t from Team join fetch t.members where t.name = '팀A'";
List<Team> teams = em.createQuery(query, Team.class).getResultList();
for (Team team : teams) {
System.out.println("teamname = " + team.getName() + ", team = " + team);
for (Member member : team.getMembers()) {
System.out.println(
"->username = " + member.getUsername() + ", member = " + member
);
}
}
/* 결과 (N + 1 문제 발생)
teamname = 팀A, team = Team@0x100
->username = 회원1, member = Member@0x200
->username = 회원2, member = Member@0x300
-----------------------------------------
teamname = 팀A, team = Team@0x100
->username = 회원1, member = Member@0x200
->username = 회원2, member = Member@0x300
*/6.4 페치 조인과 DISTINCT
JPQL의 DISTINCT는 SQL에 DISTINCT를 추가하고 애플리케이션 시점에 한 번 더 중복을 제거한다.
- 위 두 경우의 조인 테이블을 보면 결국 각각의 튜플은 중복되지 않기 때문에 SQL의
DISTINCT는 효과가 없다. - 하지만 애플리케이션 시점에서
DISTINCT명령어를 보고 중복된 데이터를 걸러낸다.
// 결과
teamname = 팀A, team = Team@0x100
->username = 회원1, member = Member@x200
->username = 회원2, member = Member@x3006.5 페치 조인 vs 일반 조인 (in. JPQL)
일반 조인: SELECT 절에 지정된 엔티티만 조회지연 로딩의 경우: 프록시나 초기화되지 않은 컬렉션 래퍼 반환 (연관된 엔티티 사용시 N + 1문제 발생)즉시 로딩의 경우: 연관된 엔티티를 가져오기 위해 쿼리를 한 번 더 실행 (처음부터 N + 1문제 발생)
페치 조인: 연관된 엔티티도 함께 조회따라서, 기본적으로 지연 로딩을 사용하고 최적화가 필요한 곳에 페치 조인을 사용하는 것이 좋다.
6.6 페치 조인의 한계
페치 조인 대상에
별칭X- 별칭을 사용해 엔티티의 일부 데이터만 가져오면 데이터 무결성이 깨질 수 있다.
둘 이상의 컬렉션을 페치할 수 없다.- 컬렉션 * 컬렉션 * 컬렉션... 만큼 만들어 지는 것을 방지
컬렉션을 페치 조인하면
페이징 API를 사용할 수 없다.- 컬렉션에 페치 조인과 페이징을 같이 적용할 경우 페치 조인된 결과 전체를 인메모리에 가져온 후 페이징을 처리하기 때문에 조인 결과가 많다면 성능 이슈와 메모리 초과 예외가 발생할 수 있어 위험하다.
6.7 페이징 API 문제 해결 방법
@ManyToOne으로 페이징 처리
//@OneToMany에서는 페이징 처리 불가
String query = "select t from Team t join fetch t.members";
//@ManyToOne으로 뒤집어서 해결
String query = "select m from Member m join fetch m.team";
List<Team> result = em.createQuery(query, Team.class)
.setFirstResult(0)
.setMaxResults(1)
.getResultList();
for (Team team : result) {
System.out.println("team = " + tem.getName() + ", members = " + team.getMembers());
for (Member member : team.getMembers()) {
System.out.println("-> member = " + member);
}
}BatchSize로 해결
- @BatchSize 애노테이션으로 해결
@Entity
public class Team {
//...
@BatchSize(size = 100)
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
}- 글로벌 설정 파일에 batchsize 설정 추가로 해결 (추천)
hibernate.default_batch_fetch_size = 100String query = "select t from Team t";
List<Team> result = em.createQuery(query, Team.class)
.setFirstResult(0)
.setMaxResults(2)
.getResultList();
for (Team team : result) {
System.out.println("team = " + tem.getName() + ", members = " + team.getMembers());
for (Member member : team.getMembers()) {
System.out.println("-> member = " + member);
}
}-- 지연로딩인 연관된 엔티티를 찾는 쿼리 (최대 batchsize만큼의 in 쿼리를 날린다.)
-- 조회한 team 엔티티들과 연관된 엔티티를 모두 한 번에 조회
select
members.TEAM_ID
members.id
...
from
Member members
where
members.TEAM_ID in (?, ?)- 단 BatchSize는 100 ~ 1000 사이를 선택하는 것을 권장한다. 만일 10000개의 데이터가 존재할 때 BatchSize를 10000으로 잡는다면 in 쿼리에 한번에 10000개의 데이터를 비교해 한번의 쿼리로 모든 데이터를 가져올 순 있지만 이 때 순간 부하가 증가하게된다. 여기서 생각해야될 점은 BatchSize를 500개만 잡는다고 해서 10000개의 데이터를 안 가져오는 것이 아니다. 단지 20개의 추가 쿼리가 나가며 대신 부하를 줄일 수 있다. 따라서 성능을 확인해 BatchSize를 적당히 주는 것이 좋다.
7. 정리
페치 조인은 객체 그래프를 유지할 때 사용하면 효과적이다.
여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야한다면 필요한 데이터만 조회해 DTO로 반환하는 것이 효과적이다. (단, 리포지토리 재사용성이 떨어짐.)
*ToOne에서 N + 1 해결
- 지연로딩 + 페치 조인을 사용
OneToMany에서 N + 1 해결
- 지연로딩 + 페치 조인 + distinct로 한번에 쿼리 (단, 페이징 불가)
- 페이징까지 고려해 지연로딩 + Batchsize로 해결
Reference
- 자바 ORM 표준 JPA 프로그래밍 [김영한]
'backend > jpa' 카테고리의 다른 글
| JPA 활용 1, 2 정리 (0) | 2023.05.04 |
|---|---|
| Ch.10 JPQL - ETC (0) | 2023.05.03 |
| CH.10 JPQL - 기본 문법 (0) | 2023.05.03 |
| Ch.9 값 타입 (0) | 2023.05.03 |
| Ch.8 프록시와 영속성 전이 (0) | 2023.05.03 |
- Total
- Today
- Yesterday
- 백준 15683
- 백준 인구 이동
- **kwargs
- 백준 14891
- 백준 경사로
- tuple method
- 백준 사다리 조작
- Unpacking
- 백준 드래곤 커브
- setmethod
- Python
- 백준 15684
- list method
- *args
- set메서드
- 파이썬
- Split
- 백준 16234
- 최소 공배수
- JOIN
- 백준 톱니바퀴
- 백준
- 백준 14890
- 백준 15685
- 최대 공약수
- 백준 치킨 배달
- 백준 15686
- 백준 감시
- 리스트 메서드
- sorted
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |